Method
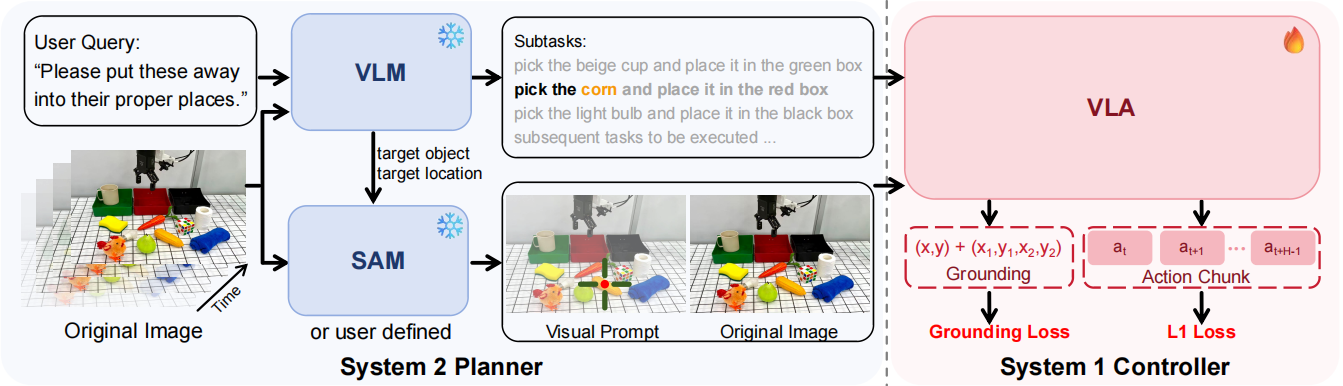
VP-VLA adopts a dual-system pipeline that decouples high-level reasoning and low-level execution via structured visual prompting: the System 2 Planner uses a VLM to decompose complex language instructions into subtasks, identifies target objects and locations, and generates structured visual prompts (crosshairs, bounding boxes) via SAM for overlay on raw images; the System 1 Controller takes language instructions, raw visual observations and visual prompt images as inputs to produce precise sensorimotor trajectories for robots. In training, it combines L1 loss for action prediction with visual grounding loss on key frames (backpropagated only to the VLM backbone), ensuring the controller aligns with the spatial cues of visual prompts and boosting the spatial precision and robustness of multi-stage manipulation.